Agent Reinforcement Trainer
ART
3/5
🧩 软硬件结合
已发布
项目简介
Agent Reinforcement Trainer: train multi-step agents for real-world tasks using GRPO. Give your agents on-the-job traini
ART(Agent Reinforcement Trainer)是一个开源的强化学习框架,旨在通过让大语言模型从实际经验中学习,显著提升多步骤智能体在真实世界任务中的可靠性。该项目由 OpenPipe 团队开发,核心采用 GRPO(Group Relative Policy Optimization)算法,为开发者提供了一套简洁易用的工具链,将强化学习无缝集成到任何 Python 应用中。
标签
项目特点
**基于 GRPO 的强化学习**:采用 Group Relative Policy Optimization 算法,让智能体在多次尝试中自我改进,不需要人工标注每一步的正确答案。
**支持 LoRA 高效微调**:通过低秩适配(LoRA)技术,只需少量显存就能微调大模型,降低训练门槛。
**真实世界任务训练**:支持浏览器操作、API 调用、代码执行等真实场景,训练出的智能体可直接用于自动化工作流。
**多步骤推理与纠错**:智能体可以自主规划多步行动,并在遇到错误时自动回溯、调整策略。
**开源可复现**:代码完全开源,提供训练脚本、配置文件和使用示例,方便研究者复现和二次开发。
**兼容主流 LLM**:支持 Llama、Qwen、Mistral 等主流开源大模型,灵活切换基座。
技术规格
项目资源
搜索资源
物料清单 (BOM)
| 物料名称 | 数量 | 参考价格 | 备注 |
|---|---|---|---|
| Python 3.10+ | 1 | — | 运行环境 |
| PyTorch 2.0+ | 1 | — | 深度学习框架 |
| vLLM 或 Transformers | 1 | — | 推理引擎 |
| Playwright | 1 | — | 浏览器自动化 |
| DeepSpeed | 1 | — | 分布式训练(可选) |
| GPU (A100 80GB 或 RTX 4090) | 1+ | — | 训练必需 |
| 内存 64GB+ | 1 | — | 推荐配置 |
| 存储 200GB+ | 1 | — | 模型与数据存储 |
| 训练轨迹数据集 | 1套 | — | JSONL 格式 |
| 基座模型 (如 Llama 3) | 1 | — | 需提前下载 |
能力画像
**记忆与知识检索**:3/5 — 智能体可调用外部知识库或搜索引擎,但本身不擅长长程记忆,依赖上下文窗口。
**动手与操作**:4/5 — 能操控浏览器、执行代码、调用 API,完成真实世界的多步骤操作任务。
**编程与算法**:4/5 — 支持代码生成与执行,可编写 Python 脚本、SQL 查询等,但复杂算法需基座模型能力支撑。
**设计与建模**:2/5 — 不直接支持 CAD 或 3D 建模,但可通过代码生成辅助设计流程。
**实验与调试**:3/5 — 具备试错和纠错能力,可在训练中自动调整策略,但调试深度有限。
**协作与分享**:2/5 — 本身是单智能体框架,不原生支持多智能体协作,但可通过 API 集成到团队工作流。
**学习与研究**:5/5 — 核心价值在于通过 GRPO 强化学习持续优化策略,适合研究强化学习与智能体结合。
**系统集成**:3/5 — 可通过 REST API 或命令行集成到现有系统,但部署配置有一定复杂度。
项目图库
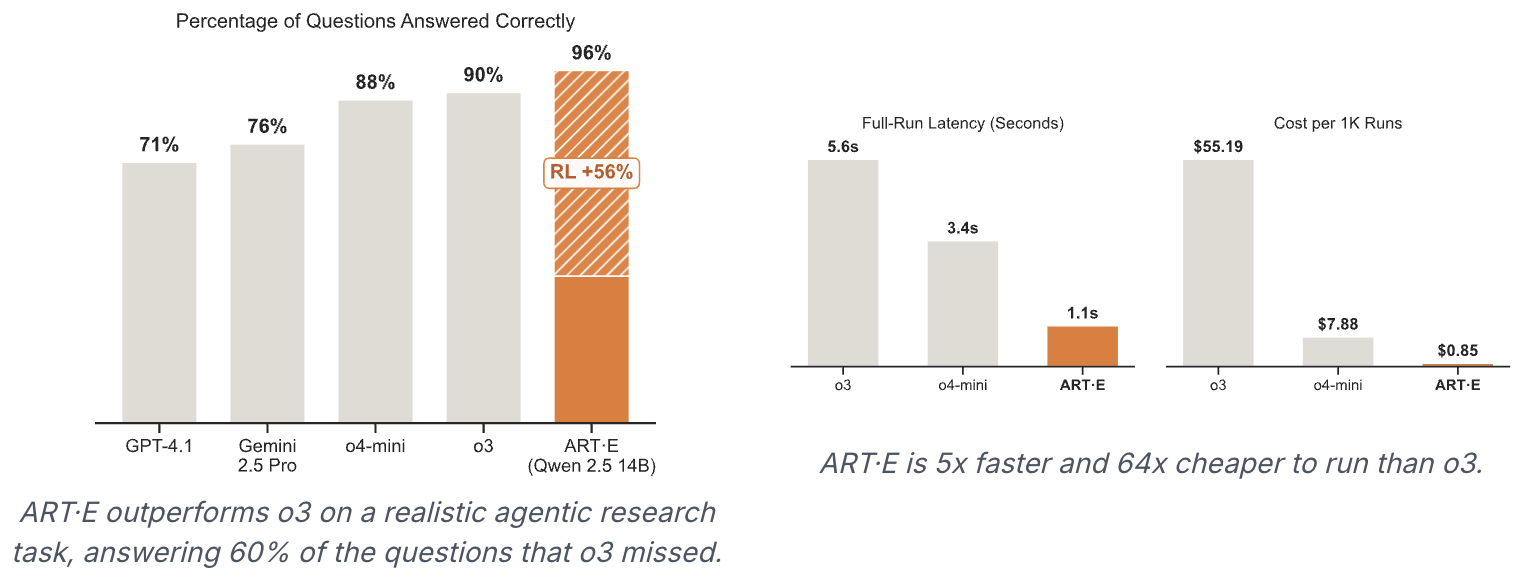









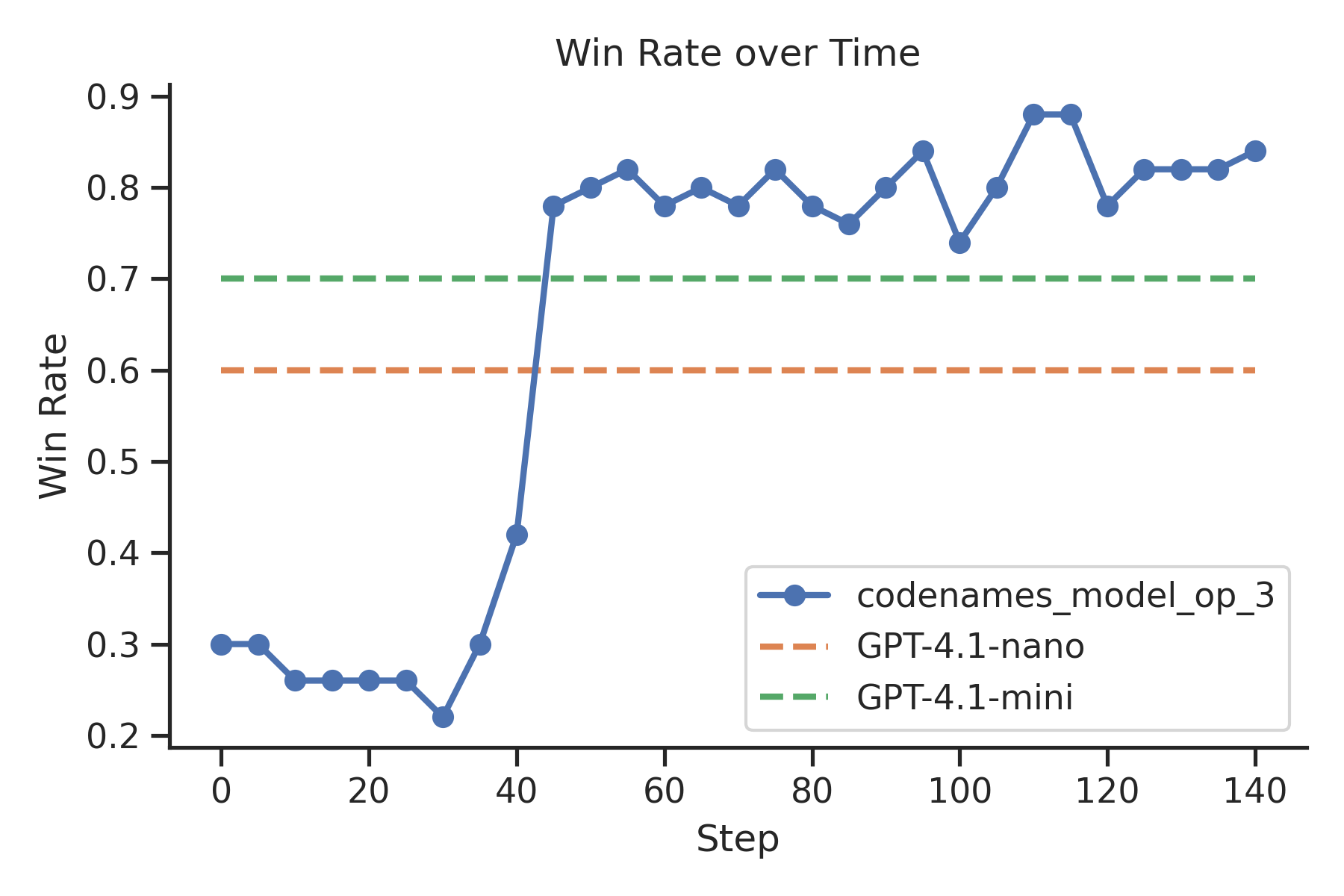
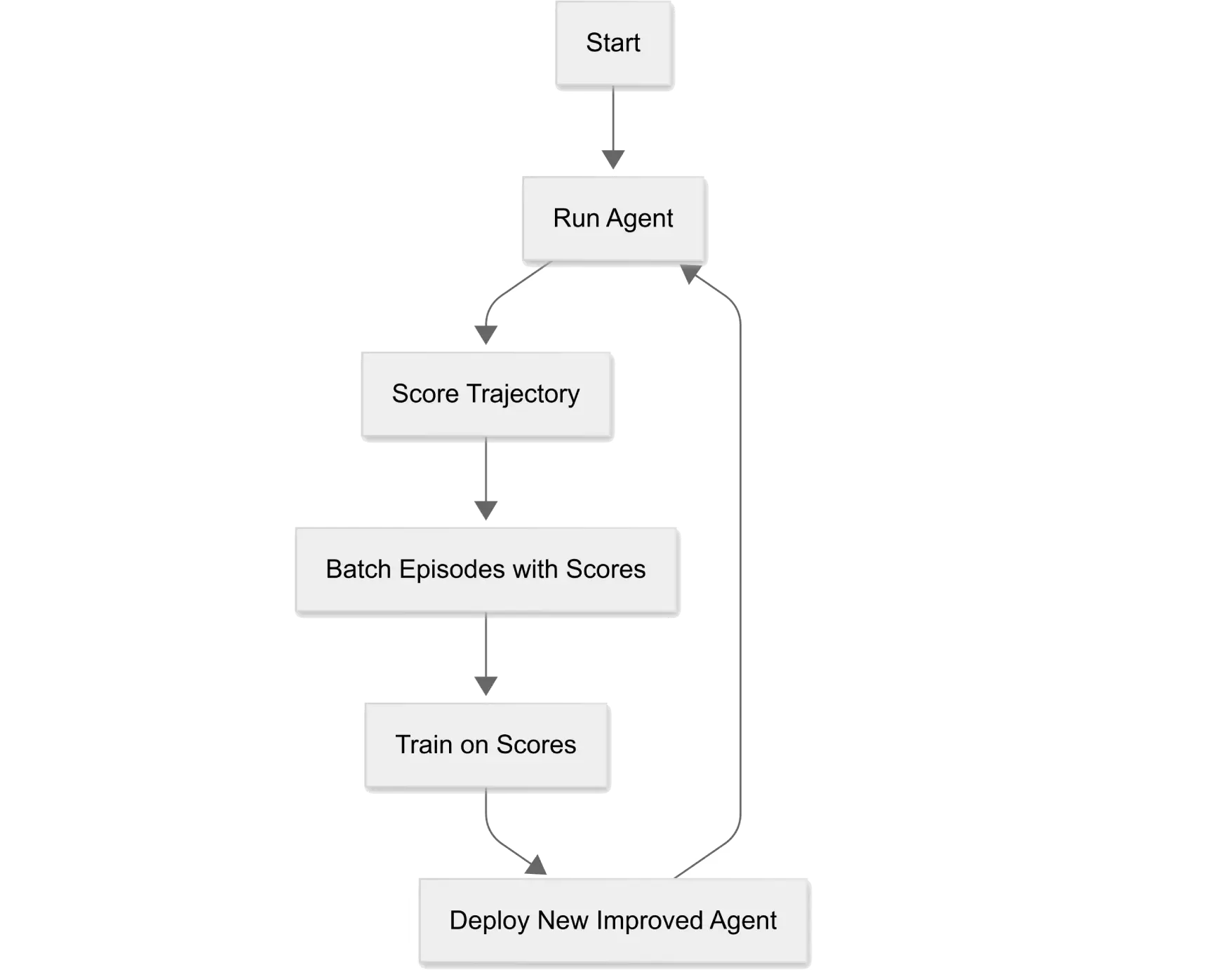
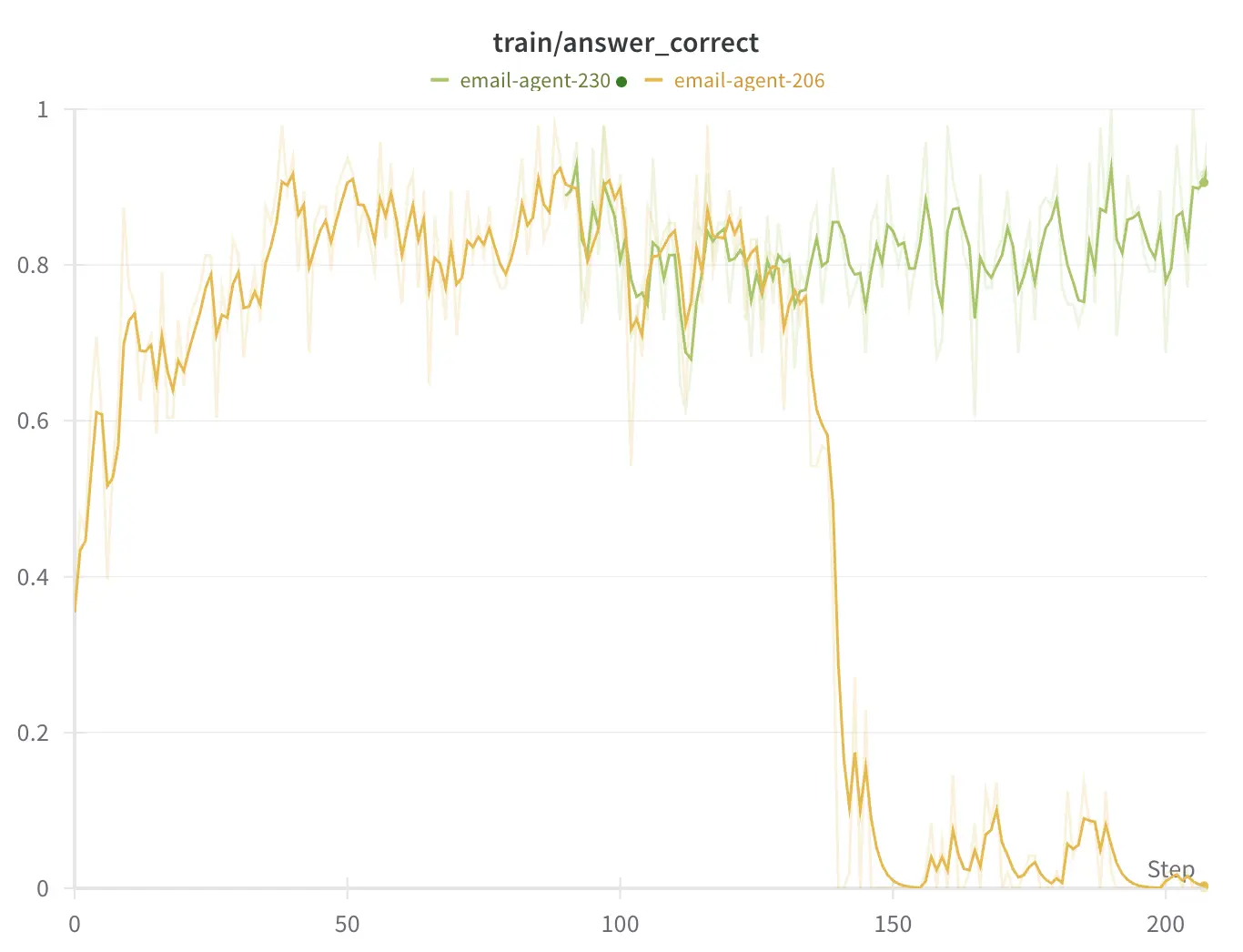
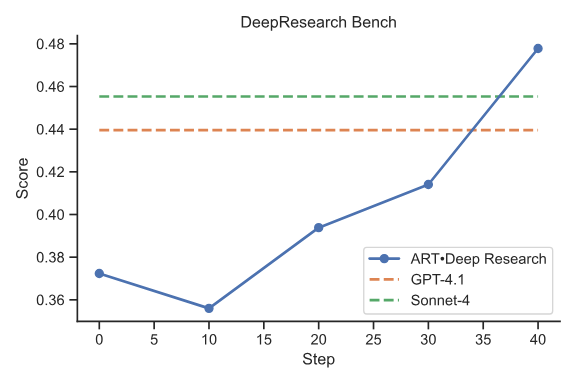
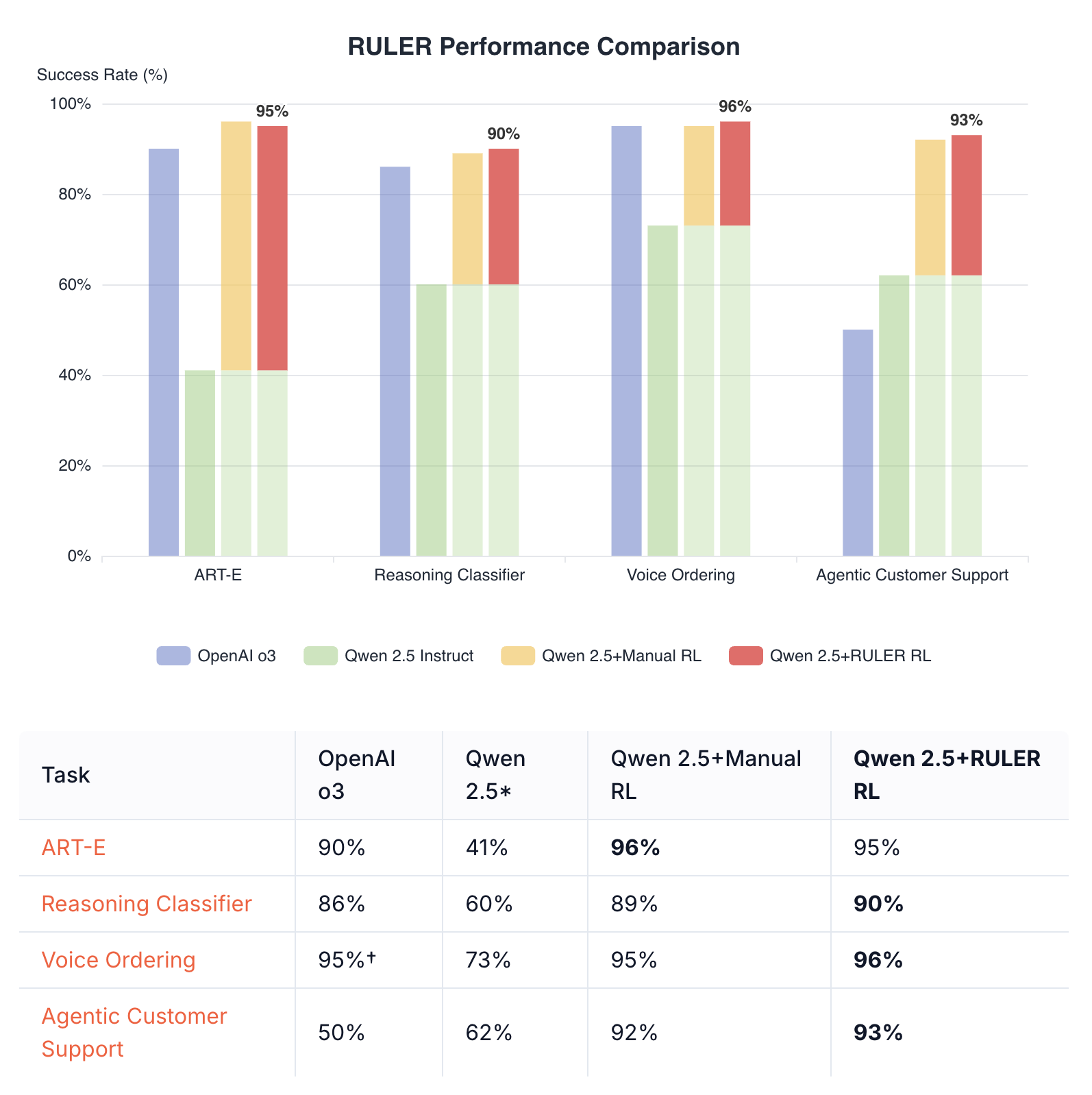

所需技能
Python 编程基础(数据处理、脚本编写)
深度学习基础(PyTorch、模型微调概念)
强化学习基本概念(策略梯度、奖励函数)
大语言模型使用经验(Hugging Face Transformers)
Linux 命令行操作(环境配置、训练启动)
分布式训练基础(DeepSpeed 使用经验为加分项)
浏览器自动化基础(Playwright 或 Selenium)
适用场景
**自动化浏览器操作**:自动填写表单、抓取网页数据、执行重复性网页任务。
**代码生成与调试**:根据自然语言描述生成代码,并自动运行测试、修复错误。
**API 编排与集成**:调用多个外部 API 完成复杂业务逻辑(如订单处理、数据同步)。
**智能客服与任务代理**:训练能自主查询数据库、发送邮件、生成报告的客服智能体。
**科研实验自动化**:自动执行实验步骤、记录结果、调整参数,加速科研流程。
**教育与培训**:作为强化学习教学案例,展示 GRPO 算法在智能体训练中的应用。