中文LLaMA&Alpaca大语言模型
Chinese-LLaMA-Alpaca
3/5
🧩 软硬件结合
已发布

项目简介
中文LLaMA&Alpaca大语言模型+本地CPU/GPU训练部署 (Chinese LLaMA & Alpaca LLMs)
中文LLaMA&Alpaca大语言模型+本地CPU/GPU训练部署 (Chinese LLaMA & Alpaca LLMs)
标签
项目特点
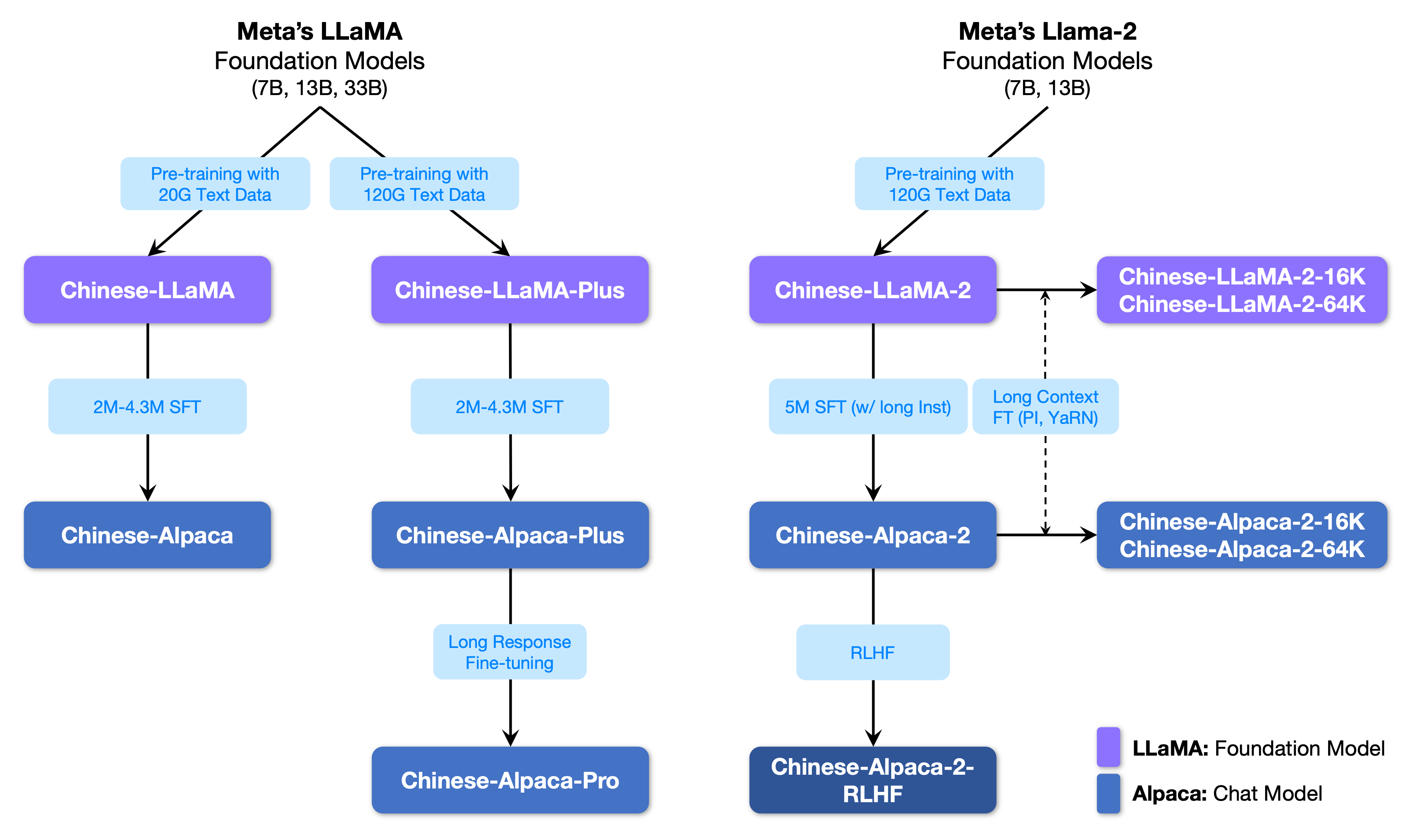
针对原版LLaMA模型扩充中文词表,提升中文编解码效率
开源使用中文文本数据预训练的中文LLaMA以及经过指令精调的中文Alpaca
开源预训练脚本和指令精调脚本,用户可根据需要进一步训练模型
支持在个人电脑的CPU/GPU上快速量化和部署大模型
兼容🤗transformers、llama.cpp、text-generation-webui、LlamaChat、LangChain、privateGPT等生态
提供LoRA权重,需与原版LLaMA模型合并后使用
技术规格
| 模型架构 | 基于LLaMA的Transformer架构 |
|---|---|
| 模型规模 | 7B、13B、33B |
| 词表大小 | 49953(中文LLaMA)/ 49954(中文Alpaca,含pad token) |
| 训练方式 | 传统CLM(LLaMA)/ 指令精调(Alpaca) |
| 训练数据 | 通用语料20G-120G(LLaMA)/ 指令数据2M-4.3M(Alpaca) |
| 模型类型 | 基座模型(LLaMA)/ 指令理解模型(Alpaca) |
| 部署方式 | CPU/GPU量化部署 |
| 支持框架 | transformers、llama.cpp、text-generation-webui、LangChain等 |
项目资源
搜索资源
物料清单 (BOM)
| 物料名称 | 数量 | 参考价格 | 备注 |
|---|---|---|---|
| 原版LLaMA模型权重 | 1 | — | 需从Facebook申请或第三方获取 |
| LoRA权重(本项目提供) | 1 | — | 从HF/ModelScope/百度网盘下载 |
| Python 3.8+ | 1 | — | 运行环境 |
| PyTorch | 1 | — | 深度学习框架 |
| transformers库 | 1 | — | 模型加载和推理 |
| llama.cpp | 1 | — | 可选,用于CPU量化部署 |
| 内存 | 8GB+ | — | 推荐16GB+ |
| 硬盘空间 | 20GB+ | — | 根据模型大小而定 |
| GPU(可选) | 1 | — | 推荐NVIDIA显卡,6GB+显存 |
能力画像
⚪ 记忆与知识检索: 4/5
🔵 逻辑推演: 3/5
⚪ 表达与交流: 4/5
⚪ 感知与观察: 1/5
⚪ 数理与计算: 3/5
⚪ 动手与操作: 2/5
⚪ 狂热与坚持: 4/5
⚪ 创造与创新: 4/5
项目图库


所需技能
🔧 **动手能力**:需要掌握Python环境配置、模型下载与合并、量化部署等操作,具备基本的命令行使用能力
💻 **编程能力**:需要Python编程基础,了解PyTorch和transformers库的使用,能够运行和修改训练/推理脚本
⚡ **电子电路**:不涉及
适用场景
中文自然语言处理研究和实验
在本地部署中文大语言模型进行问答、写作、建议等任务
基于LLaMA/Alpaca进行领域微调或二次开发
教育和学习大语言模型的训练和部署流程
构建基于LangChain等框架的中文AI应用