Vision Transformer PyTorch实现
vit-pytorch
3/5
🧩 软硬件结合
已发布
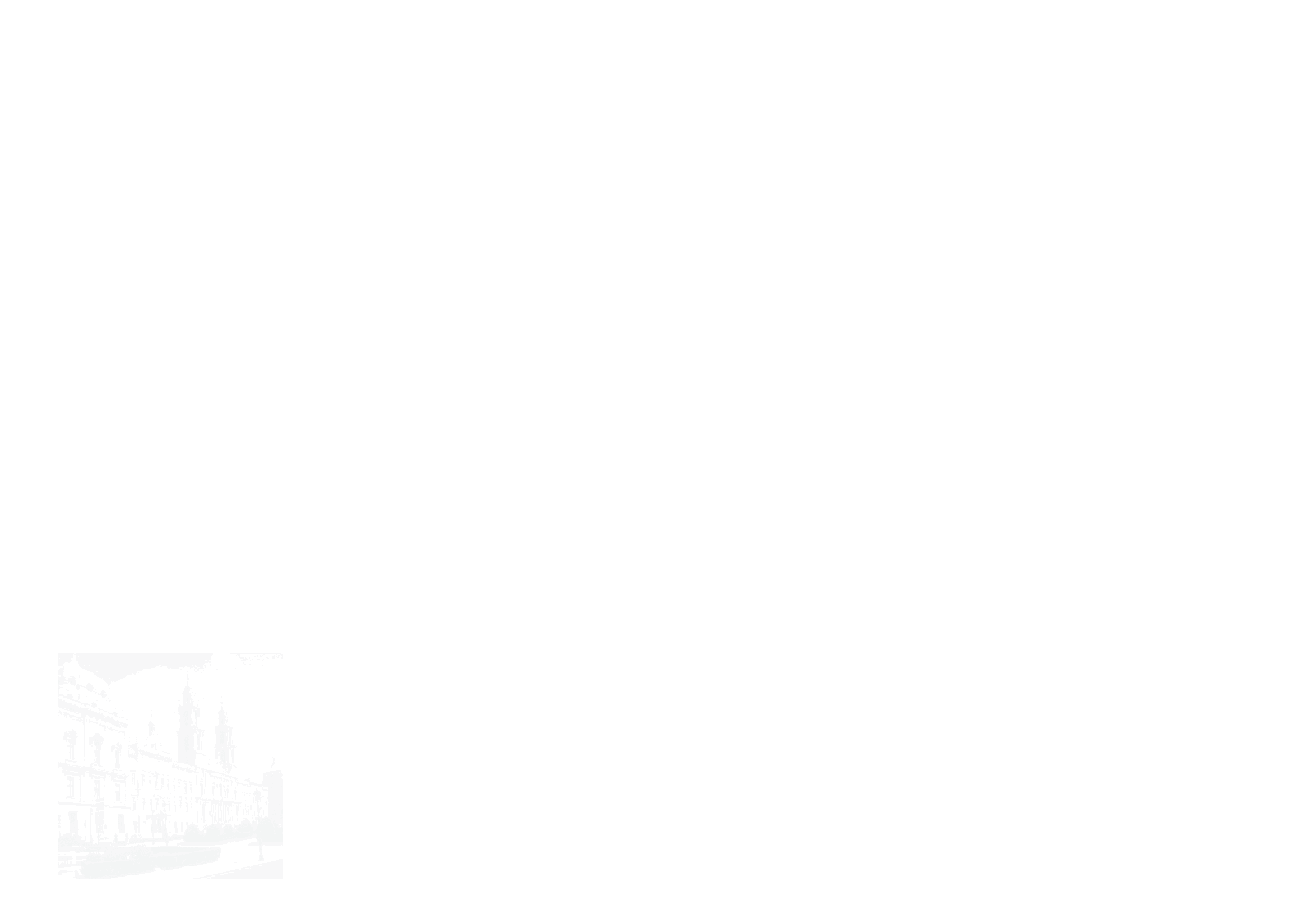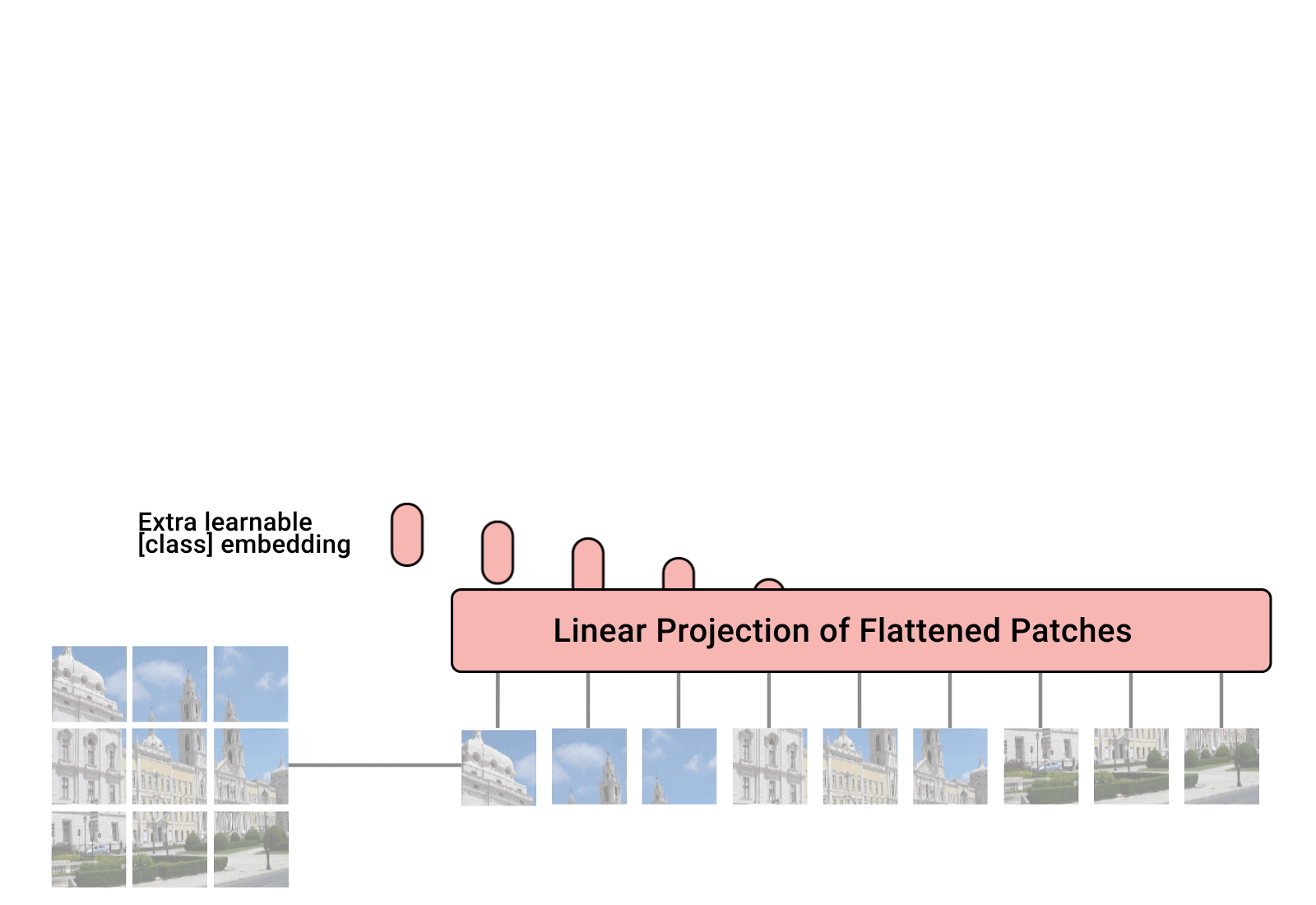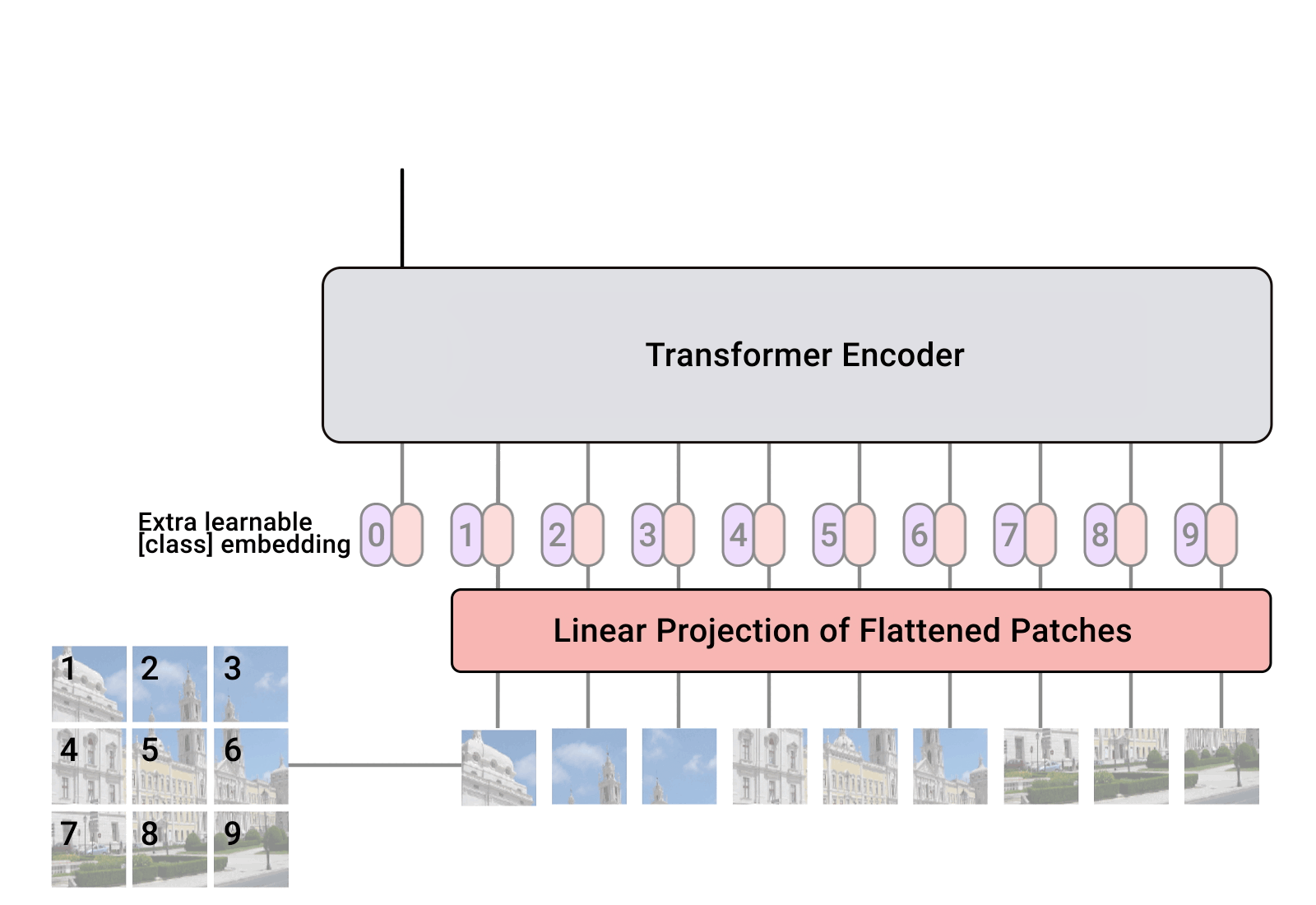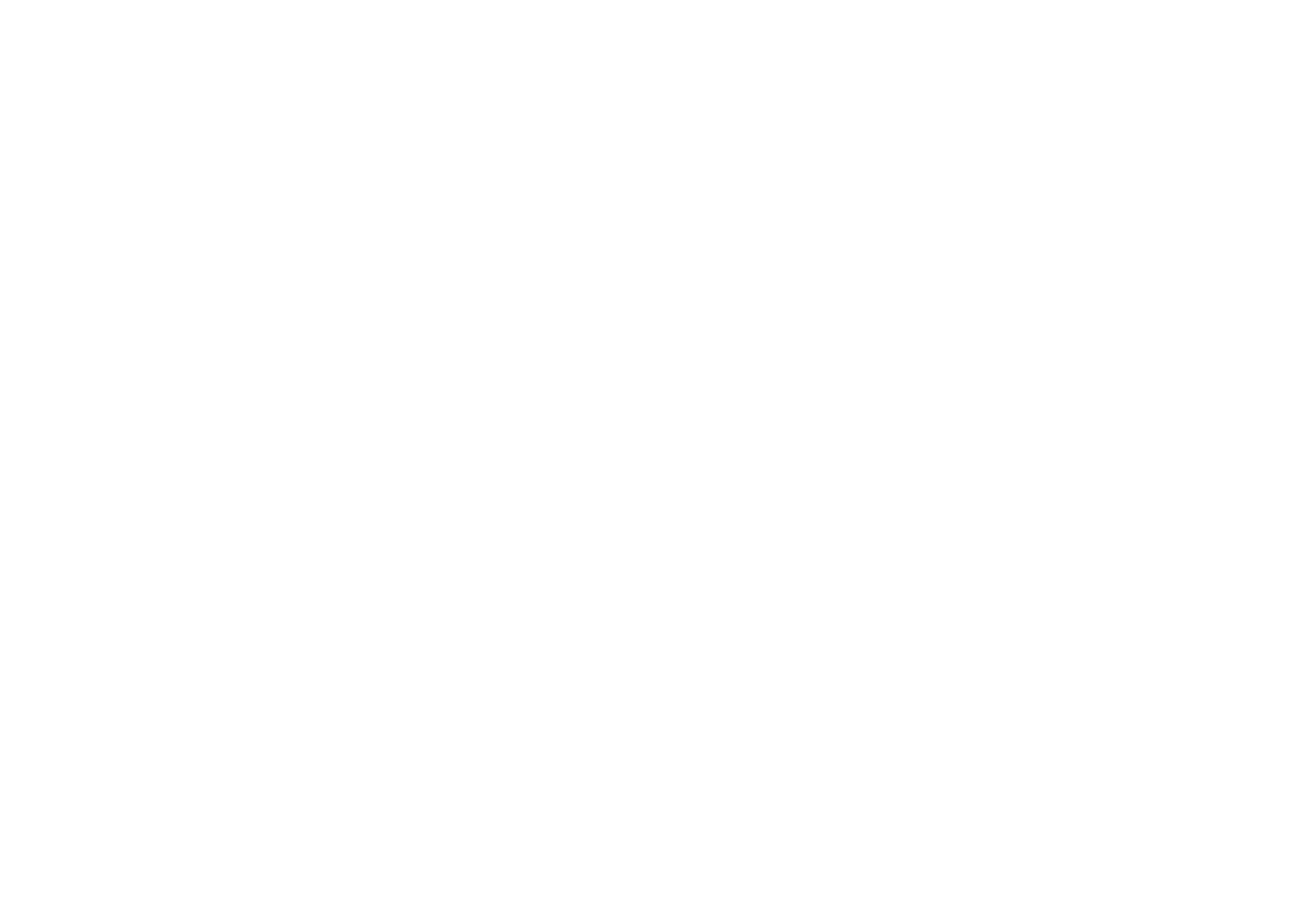
项目简介
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transform
Vision Transformer (ViT) 的 PyTorch 实现,是一个将 Transformer 架构成功应用于计算机视觉领域的开源项目。该项目由开发者 Phil Wang 维护,核心功能是提供简洁、模块化的代码,让用户能够轻松构建和实验各种基于 Vision Transformer 的图像分类模型。
标签
项目特点
提供完整的 Vision Transformer 基础实现,代码简洁易用
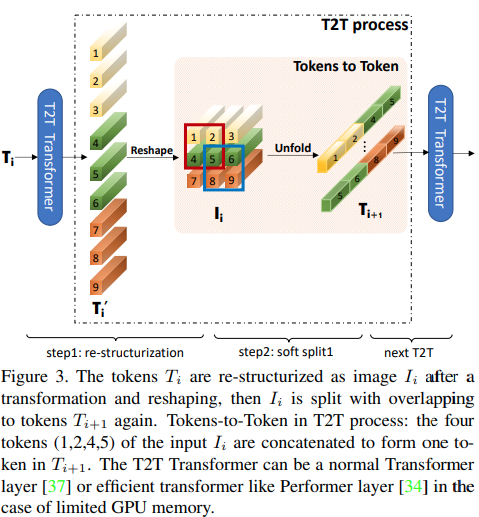
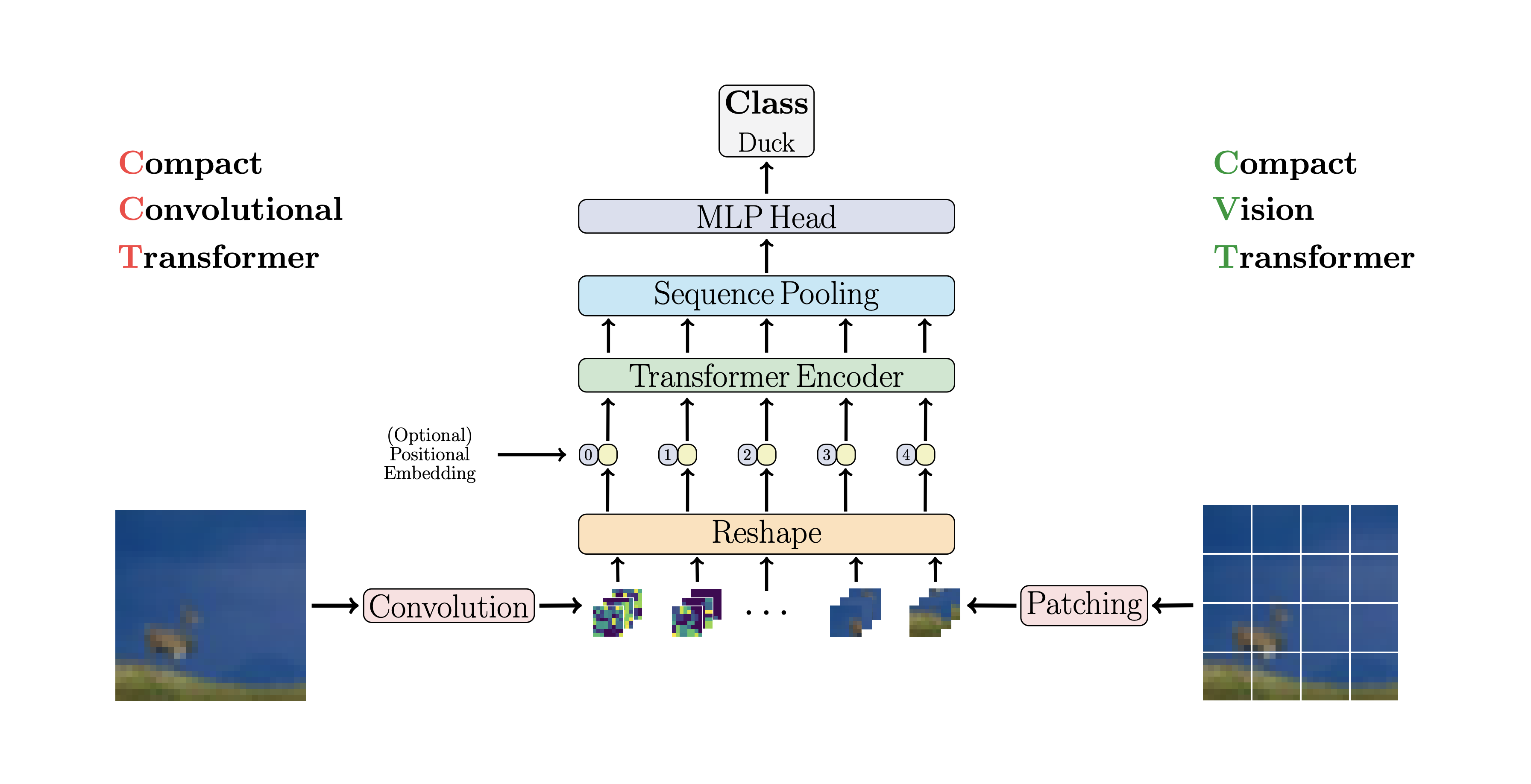
包含大量 ViT 变体实现,如 SimpleViT、NaViT、CaiT、DeepViT、CCT、MobileViT 等
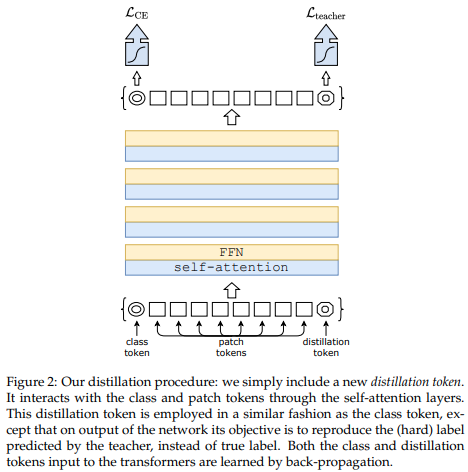
支持知识蒸馏功能,可从卷积网络向 ViT 蒸馏知识
提供掩码自编码器(MAE)等自监督学习实现
支持多种注意力机制改进,如 Re-attention、Talking Heads 等
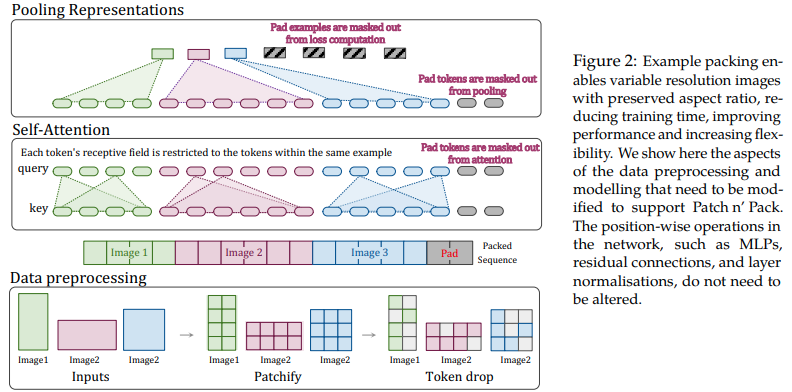
兼容不同分辨率的图像输入(NaViT)
提供嵌套张量(Nested Tensor)支持,优化序列处理
技术规格
| image_size | 图像尺寸,必须能被 patch_size 整除 |
|---|---|
| patch_size | 图像块大小,图像尺寸必须能被其整除 |
| num_classes | 分类类别数 |
| dim | Transformer 输出维度 |
| depth | Transformer 块的数量 |
| heads | 多头注意力层头数 |
| mlp_dim | MLP(前馈)层维度 |
| channels | 图像通道数,默认 3 |
| dropout | Dropout 率,范围 [0, 1],默认 0 |
| emb_dropout | 嵌入层 Dropout 率,范围 [0, 1],默认 0 |
| pool | 池化方式,可选 cls token 池化或 mean 池化 |
项目资源
搜索资源
物料清单 (BOM)
| 物料名称 | 数量 | 参考价格 | 备注 |
|---|---|---|---|
| Python | 1 | — | 编程语言 |
| PyTorch | 1 | — | 深度学习框架 |
| vit-pytorch | 1 | — | 通过 pip 安装 |
能力画像
⚪ 记忆与知识检索: 1/5
🔵 逻辑推演: 3/5
⚪ 表达与交流: 1/5
⚪ 感知与观察: 1/5
🔵 数理与计算: 4/5
🔵 动手与操作: 2/5
⚪ 狂热与坚持: 2/5
🔵 创造与创新: 3/5
项目图库

所需技能
🔧 **动手能力**:需要能够配置 Python 和 PyTorch 环境,安装依赖包
💻 **编程能力**:需要 Python 编程基础,理解 PyTorch 框架使用,了解 Transformer 架构原理
⚡ **电子电路**:不涉及
适用场景
图像分类任务的研究与实验
计算机视觉领域的 Transformer 架构探索
自监督学习(掩码自编码器)研究
知识蒸馏实验,从卷积网络向 Transformer 迁移知识
多分辨率图像处理研究