LoRAX
lorax
3/5
🧩 软硬件结合
已发布
项目简介
Multi-LoRA inference server that scales to 1000s of fine-tuned LLMs
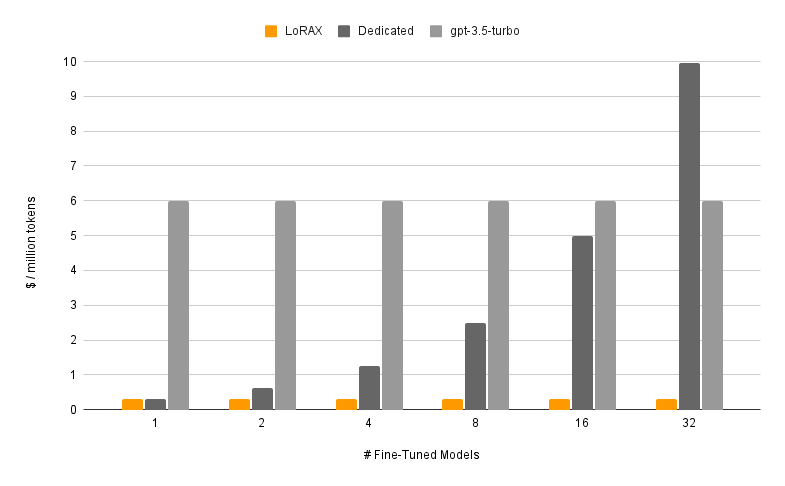
LoRAX是一个专注于高效服务大规模微调语言模型的开源推理框架,由Predibase团队开发并采用Apache 2.0许可证。它的核心创新在于:仅需一块GPU,就能同时承载数千个经过LoRA微调的模型,大幅降低部署成本,同时保持高吞吐和低延迟。
标签
项目特点
🚅 **动态适配器加载**:支持从HuggingFace、Predibase或任何文件系统动态加载LoRA适配器,无需阻塞并发请求。还支持按请求合并适配器,创建强大的集成模型。
🏋️♀️ **异构连续批处理**:将不同适配器的请求打包到同一批次中,使延迟和吞吐量几乎不随并发适配器数量变化。
🧁 **适配器交换调度**:异步预取和卸载GPU与CPU内存之间的适配器,调度请求批处理以优化系统的总吞吐量。
👬 **优化推理**:包括张量并行、预编译CUDA内核(flash-attention、paged attention、SGMV)、量化、令牌流等优化,实现高吞吐量和低延迟。
🚢 **生产就绪**:提供预构建的Docker镜像、Kubernetes Helm Charts、Prometheus指标和OpenTelemetry分布式追踪。支持OpenAI兼容API和多轮对话。通过按请求租户隔离实现私有适配器。支持结构化输出(JSON模式)。
🤯 **免费商业使用**:Apache 2.0许可证。
技术规格
| 基础模型支持 | Llama (包括CodeLlama)、Mistral (包括Zephyr)、Qwen等 |
|---|---|
| 适配器类型 | 使用PEFT或Ludwig训练的LoRA适配器 |
| 量化支持 | fp16、bitsandbytes、GPT-Q、AWQ |
| 硬件要求 | Nvidia GPU (Ampere代及以上)、CUDA 11.8+、Linux OS |
| 部署方式 | Docker、Kubernetes、SkyPilot、本地 |
| API | REST API、Python客户端、OpenAI兼容API |
| 监控 | Prometheus指标、OpenTelemetry分布式追踪 |
| 许可证 | Apache 2.0 |
项目资源
搜索资源
物料清单 (BOM)
| 物料名称 | 数量 | 参考价格 | 备注 |
|---|---|---|---|
| Docker | 1 | — | 推荐部署方式 |
| nvidia-container-toolkit | 1 | — | 必需 |
| Nvidia GPU (Ampere+) | 1 | — | 最低要求 |
| CUDA 11.8+ | 1 | — | 必需 |
| Linux OS | 1 | — | 必需 |
能力画像
⚪ 记忆与知识检索: 1/5
🔵 逻辑推演: 3/5
⚪ 表达与交流: 1/5
⚪ 感知与观察: 1/5
🔵 数理与计算: 4/5
🔵 动手与操作: 4/5
🔵 狂热与坚持: 3/5
🔵 创造与创新: 4/5
项目图库

所需技能
🔧 **动手能力**:需要熟悉Docker和Linux命令行操作,能够配置GPU环境和部署容器化服务。
💻 **编程能力**:需要掌握Python编程,了解REST API调用和OpenAI API集成。对PyTorch和HuggingFace生态有一定了解更佳。
⚡ **电子电路**:不适用。
适用场景
需要同时服务大量不同微调LLM的AI平台或SaaS服务
在有限GPU资源下部署多个LoRA微调模型的生产环境
研究和实验不同LoRA适配器的效果对比
构建支持多租户和私有适配器的LLM推理服务