Once-for-All (OFA) 神经网络
once-for-all
嵌入AI
3/5
🧩 软硬件结合
已发布

项目简介
[ICLR 2020] Once for All: Train One Network and Specialize it for Efficient Deployment
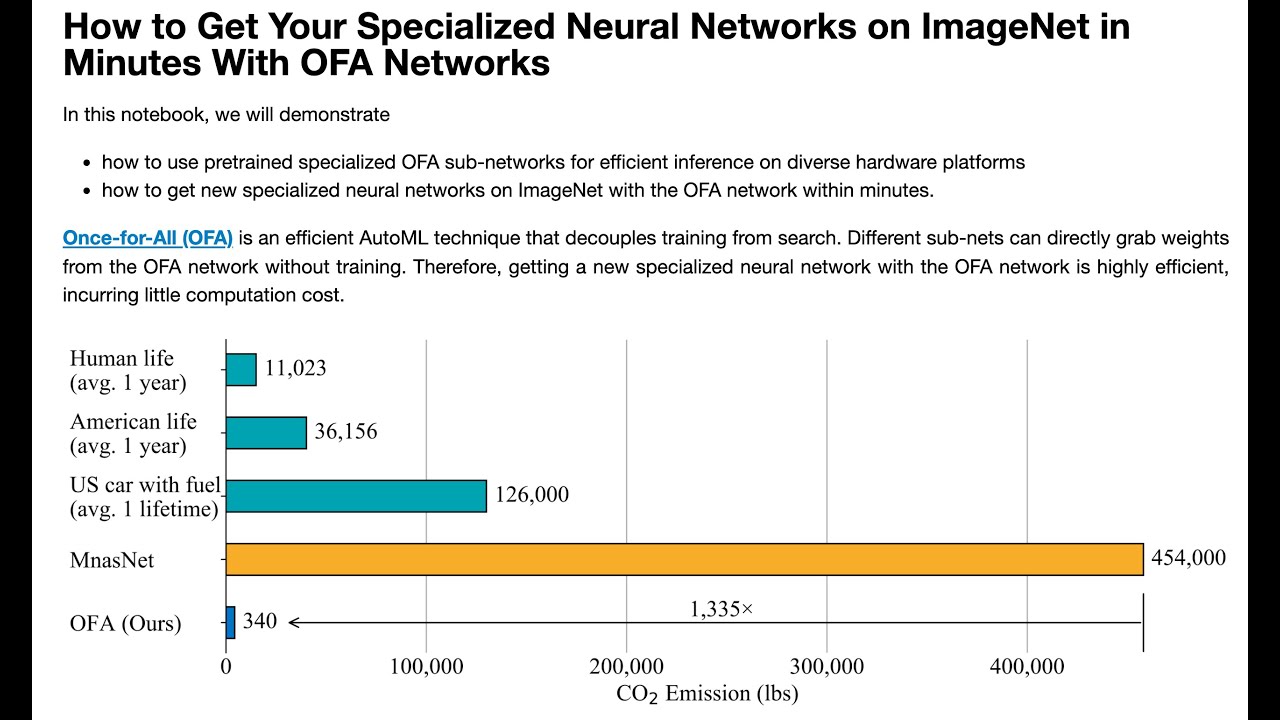
Once-for-All(OFA)是由MIT韩松团队提出的高效神经网络架构搜索与部署框架,其核心理念是“一次训练,多处部署”。传统方法需要针对不同硬件平台(如手机、边缘设备、云端GPU)分别训练多个专用模型,耗时且资源消耗巨大。OFA通过训练一个包含所有子网络(sub-network)的超网络(supernet),在推理时无需重新训练即可直接从中提取出适配特定硬件约束的子模型,大幅降低了部署成本。
标签
项目特点
**一次训练,多处部署**:训练一个超网络,即可为多种硬件平台(手机、GPU、CPU、边缘设备)和延迟约束生成专用子网络,无需为每个场景单独训练。
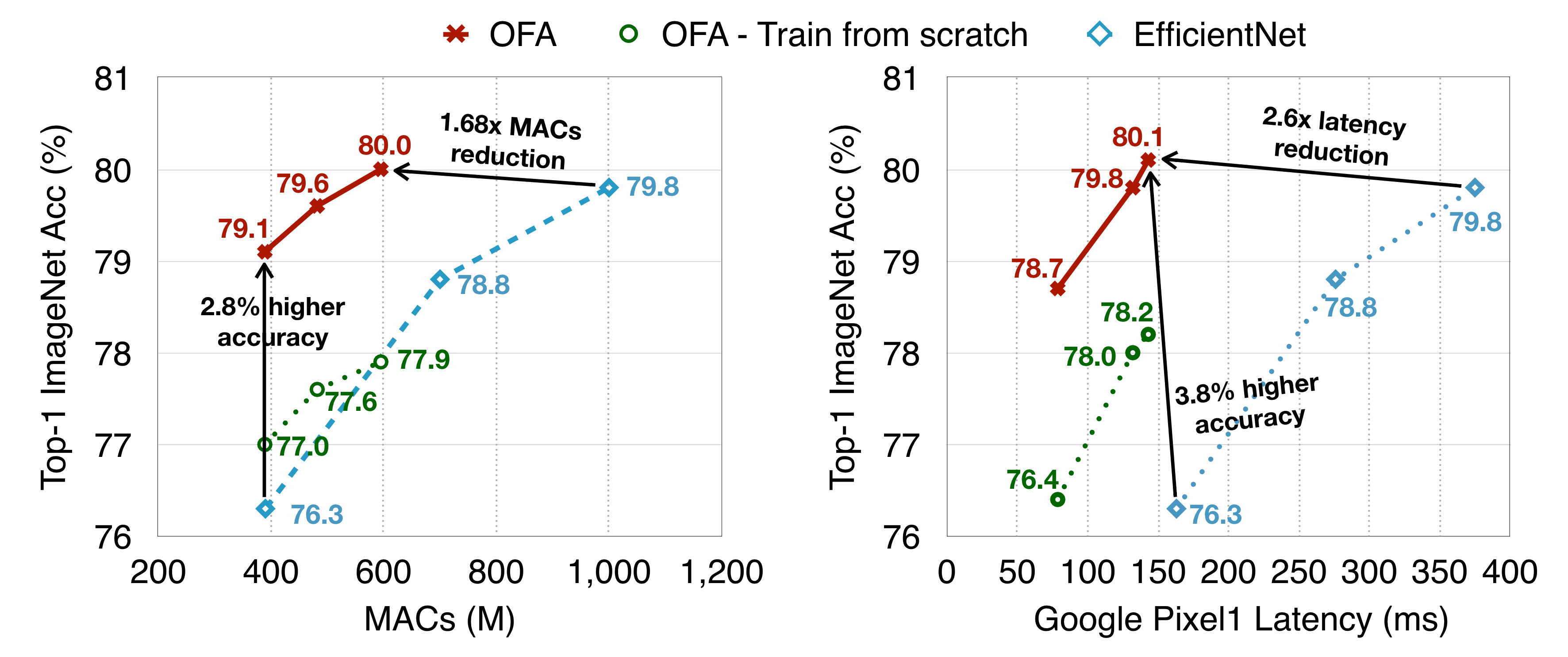
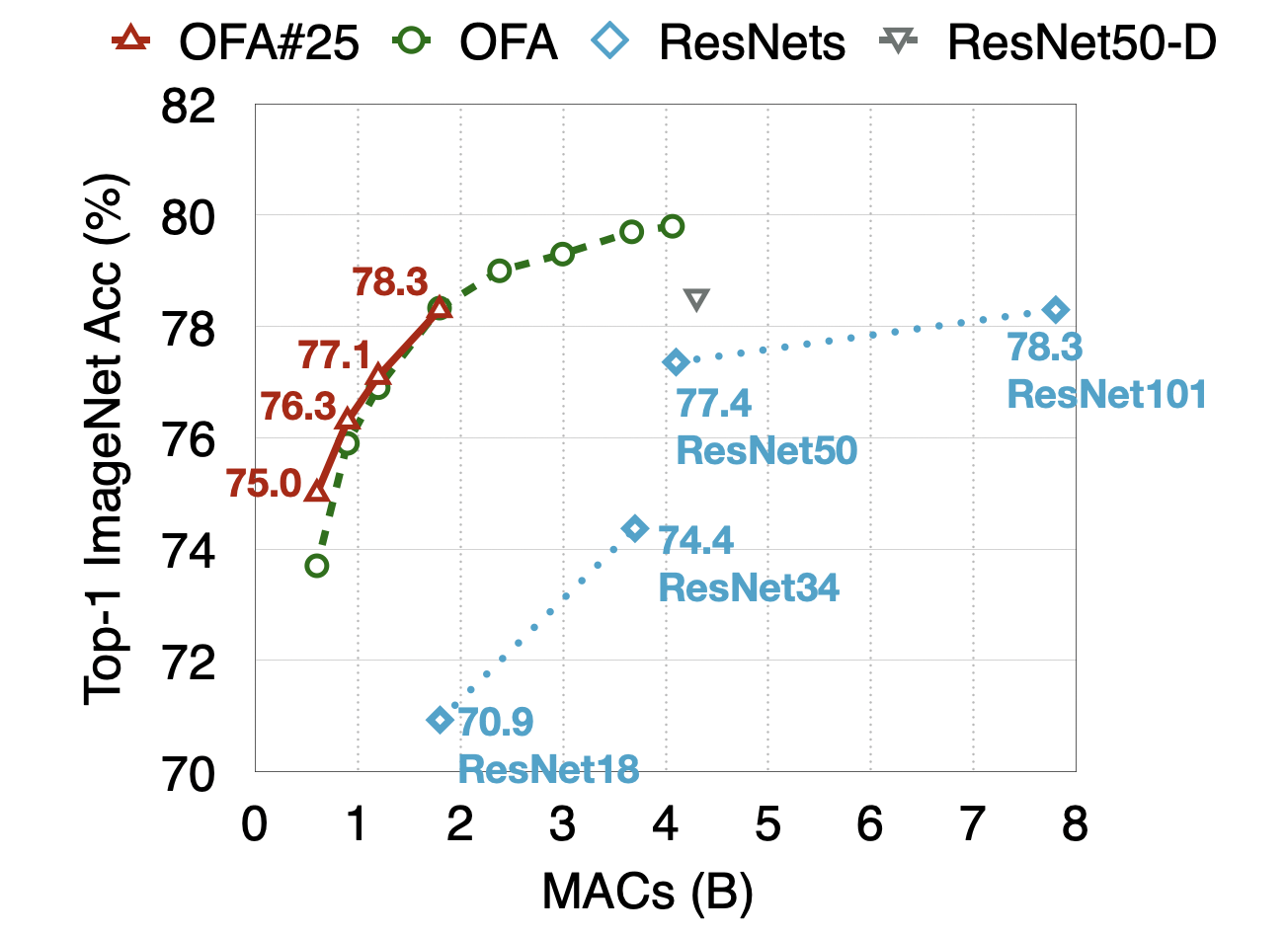
**高精度与高效率**:在 ImageNet 上达到 80% 的 Top-1 精度,同时模型参数量和计算量(MACs)远低于传统模型,如 MobileNetV3。
**灵活的架构设计空间**:支持对深度、宽度、核大小和分辨率等多个维度进行搜索,覆盖 ResNet50 和 MobileNetV3 等多种设计空间。
**即插即用**:通过 pip 安装,提供预训练模型和简洁的 Python API,方便用户直接使用或微调。
**广泛的硬件支持**:已在 LG G8、Samsung Note10、Google Pixel、Jetson TX2、Intel Xeon CPU、NVIDIA GPU 等多种硬件上验证并优化。
技术规格
| 论文 | [Once for All: Train One Network and Specialize it for Efficient Deployment](https://arxiv.org/abs/1908.09791) |
|---|---|
| 发表会议 | ICLR 2020 |
| 框架 | PyTorch 1.4.0+ |
| 支持的设计空间 | ResNet50D, MobileNetV3, ProxylessNAS |
| 搜索维度 | 深度 (Depth), 扩展比 (Expand Ratio), 核大小 (Kernel Size), 宽度 (Width Multiplier), 分辨率 (Resolution) |
| 最高 ImageNet Top-1 精度 | 80.2% (OFA-Note10-64) |
| 最小模型 MACs | 66M (OFA-S7Edge-29) |
| 最小模型参数量 | 3.8M (OFA-S7Edge-29) |
| 依赖库 | Python 3.6+, PyTorch, Horovod (用于分布式训练) |
项目资源
搜索资源
物料清单 (BOM)
| 物料名称 | 数量 | 参考价格 | 备注 |
|---|---|---|---|
| Python 3.6+ | 1 | — | 编程语言环境 |
| PyTorch 1.4.0+ | 1 | — | 深度学习框架 |
| Horovod | 1 | — | 分布式训练框架(可选,用于训练) |
| ImageNet 数据集 | 1 | — | 用于训练和评估 |
| GPU (推荐) | 1+ | — | 用于模型训练和推理 |
能力画像
⚪ 记忆与知识检索: 1/5
🔵 逻辑推演: 1/5
⚪ 表达与交流: 1/5
⚪ 感知与观察: 1/5
🔵 数理与计算: 5/5
🔵 动手与操作: 3/5
🔵 狂热与坚持: 4/5
🔵 创造与创新: 5/5
项目图库




视频
所需技能
🔧 **动手能力**:需要能够配置 Python 和 PyTorch 环境,运行训练和评估脚本。对于分布式训练,需要具备一定的集群管理能力。
💻 **编程能力**:需要熟练掌握 Python 编程,理解 PyTorch 框架,能够阅读和修改模型代码。
⚡ **电子电路**:不涉及。
适用场景
**移动端 AI 应用**:为手机、平板等资源受限设备部署高效的图像分类、目标检测模型。
**边缘计算**:在 Jetson TX2、树莓派等边缘设备上运行低延迟、高精度的 AI 模型。
**云端推理优化**:在 GPU 或 CPU 服务器上部署模型,以降低计算成本和延迟。
**模型压缩与加速**:研究或应用神经网络架构搜索(NAS)和模型剪枝技术。
**多硬件平台适配**:需要一套模型方案同时适配多种不同性能的硬件。